




Manual
do
Maker
.
com
Deep Learning com Keras - Primeira rede neural


Se você venceu a batalha do artigo anterior, é hora de começar a escarafunchar os recursos do Keras em busca de compreensão. É o que estou fazendo agora, criando classificações simples para ver a coisa funcionando.
Para fazer um treinamento, precisamos de dados. Tendo os dados, precisamos lê-los para dentro do programa, então construir a estrutura de neurônios. Vamos desde o princípio para facilitar, estou certo que precisarei referenciar-me novamente por algumas vezes até que se torne um procedimento comum.
Carregamento de dados
Os dados podem ser carregados a partir de banco de dados ou arquivos. É fácil encontrar alguns arquivos no formato csv para fazer esses treinamentos. O arquivo pode ser carregado local ou remotamente. Em um dos treinamentos que estou estudando o exemplo trata de classificação de vinhos. O arquivo está sendo carregado com o Pandas, da seguinte maneira:
import pandas as pd
# Read in white wine data
white = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv", sep=';')
# Read in red wine data
red = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv", sep=';')
Essa é uma das vantagens em utilizar Python para programar redes neurais. Já é bastante complicado fazer a modelagem, a programação não pode ser um ponto a consumir tempo ou causar preocupação.
O mais interessante em utilizar o Pandas para carregar os dados é que ele oferece funções para análise dos dados. Isso é uma mão na roda, uma vez que não será necessário criar uma função para essa visualização. Claro que deve-se dar atenção à consistência dos dados. Se algo estiver mal formatado, campo vazio, linhas com campos ausentes ou valores invertidos, tudo irá por água abaixo.
Para visualizar a estrutura de dados importada, utilizamos a função info do nosso objeto:
print(white.info())
O que deve retornar algo semelhante a isto:


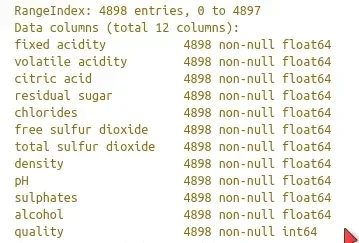
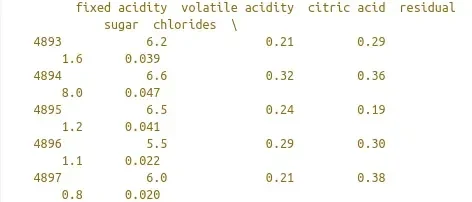
Analisar a estrutura dos dados é fundamental, como supracitado. É fundamental termos consistência nos dados que estamos carregando e alguns recursos dos Pandas nos ajudam a fazer essa análise. Por exemplo, a função tail:
print(white.tail())
Que deve retornar algo como:


Outras funções úteis são:
head()
sample(number\_of\_samples)
describe()
isnull(data\_set)
As funções head, tail e sample simplificam a visualização. A função describe() é um sumário estatístico para auxílio na avaliação da qualidade dos dados. A função isnull() ajuda a encontrar falhas na estrutura de forma mais perceptível.
Visualização de dados
Visualizar os dados é algo de extrema importância, ainda mais se forem dados complexos ou, ainda que dados simples, mas se forem apresentados a alguém.
matplotlib
É comum utilizar o matplotlib para isso, mas vamos deixar a visualização para frente, quero manter o foco no processo de manipulação e criação da rede neural primeiro.
seaborn
Para análise dos dados, podemos utilizar uma matriz de correlação, com a biblioteca seaborn. A concatenação das duas estruturas referenciadas podem ser vistas em um heatmap como esse:


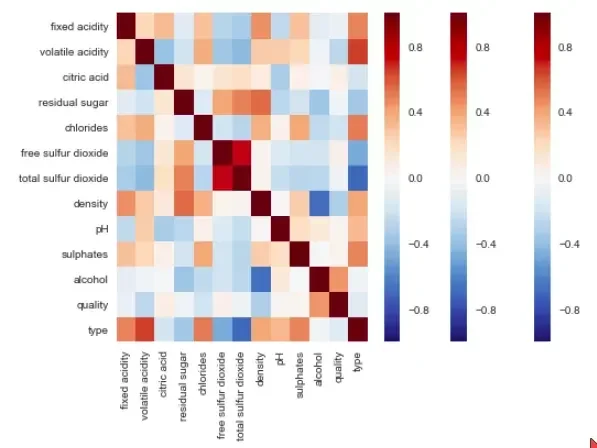
Só para exemplificar a simplicidade de utilização do recurso, eis um código de exemplo:
import seaborn as sns
corr = wines.corr()
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)
sns.plt.show()
Atente-se que até aqui estamos apenas analisando a estrutura de dados.
Cruzando referências
Outra coisa que certamente acontecerá em diversas ocasiões é a soma de estruturas de dados para uma análise maior. Utilizando o exemplo acima, a junção dessas bases poderia ser feita de uma forma bastante simples, com 3 linhas de código:
red['type'] = 1
white['type'] = 0
wines = red.append(white,ignore_index=True)
Utilizando o parâmetro ignore_index excluímos de write os índices, que nesse caso é fundamental para que não sejam duplicados. É muito semelhante à estrutura de um banco de dados, precisamos manter a consistência.
Equilíbrio dos dados
É importante que haja um equilíbrio dos dados para a classificação. Uma pequena diferença pode ser ignorada, mas quanto maior a proporcionalidade, melhor. Um desequilíbrio nos dados pode favorecer um determinado tipo de dado, por isso é necessário preocupar-se com a proporção dos tipos na classificação.
Padronização de dados
Repare que até agora estamos preparando e analisando os dados para evitar falso-positivo e outras inconsistências.
Para ajudar na padronização de dados, podemos utilizar mais 2 recursos. Não estará absolutamente claro nesse exemplo, mas ficará quando da sua utilização em um código completo. O importante agora é saber o que significa o recurso para que na leitura do código de uma classificação não tenhamos dúvidas do que está sendo feito.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(X_train)
X_train = scaler.transform(X_train)
Os dados agora estão como uma gaveta de camisetas passadas e dobradas, todas dobradas da mesma forma e empilhadas na mesma altura. Coisa linda! Agora é hora de por a mão na massa e começar a contruir a rede neural.
Classificação binária
Estou focando em 2 exemplos de meus estudos, com classificação binária. Uma delas se trata da predição da possibilidade de uma pessoa ter diabetes, baseado em parâmetros descritos no exemplo, que disporei mais adiante. O outro, é a simples distinção do tipo do vinho (vermelho ou branco) baseando-se em suas propriedades químicas.
Quando falamos de dados binários, entenda-se 0 ou 1; sim ou não; verdadeiro ou falso.
Perceptron multicamada
No artigo anterior Deep Learning com Keras descrevi o perceptron e a multicamada. Essa será a rede neural utilizada para fazer essa classificação. Em 3 casos seguidos, a função de ativação utilizada foi a mesma, sendo a mais comum. A relu. Vou descrever superficialmente e a cada artigo que for utilizando recursos, descrevo em mais detalhes, para poder fixar na mente.
Função de ativação
No artigo anterior incluí a estrutura de um neurônio. A função de ativação é escolhida conforme a necessidade, vou tentar mostrar isso de uma maneira interessante em outro artigo. Das funções, temos:
Sigmoid
Essa função é utilizada quando existe a necessidade de predição de probabilidade na saída, sendo qualquer coisa entre 0e 1. Eu compreendo melhor nessa frase do que com um gráfico, mas acredito que pode não ser a melhor forma de compreender. Também não acho que um gráfico elucide todas as dúvidas, melhor mesmo é exemplo, mas apenas para complementar o material, disponho um gráfico. Não se preocupe, quando formos utilizar, ficará muito claro.


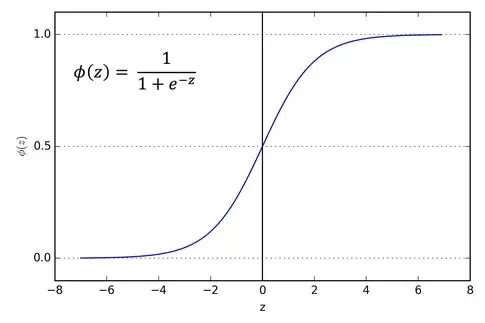
Com diferenciação dessa função podemos encontrar a inclinação de uma curva. Utilizar essa funcão de ativação tabém significa uma carga extra no processamento dos dados.
A função softmax é mais genérica, usada em classificação multiclasse. Não ficou claro agora, não tente decorar nada, apenas guarde a informação sem nenhum compromisso com ela nesse momento.
Tanh
Tangente hiperbólica é como a somatória logística, de -1 a 1. Não posso afirmar que o seja, mas lí explicitamente que "ela é melhor que a função sigmoid". Veremos.
Essa função é especialmente utilizda em classificações entre duas classes.
ReLU
É a que utilizaremos, pelo menos nos primeiros 2 exemplos.
Essa é a função mais utilizada no mundo, em quase todas as redes convolucionais ou deep learning. Essa função é "meio retificada". $latex f(z)$ é 0 quando z é menor do que zero e $latex f(z)$ é igual a z quando z é igual ou maior que 0.
A faixa vai de 0 à infinito.


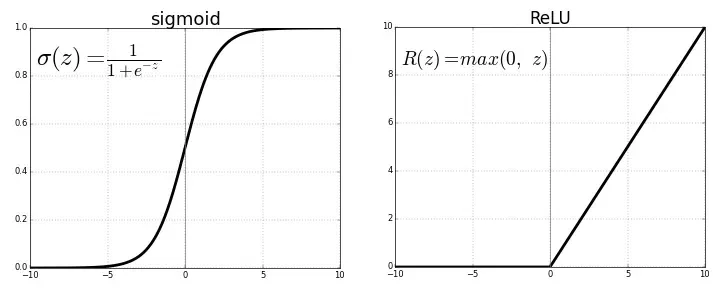
Qualquer valor negativo para o ReLU automaticamente será 0. Por enquanto é só, veremos onde pode não ser adequado no momento certo, em algum outro artigo.
Acredite, tem muita coisa e muita complexidade em tudo. Estou ignorando tudo o mais para conseguir formar uma compreensão e posteriormente, conforme for tendo domínio, farei diversos aprofundamentos. Com pouca coisa já será possível criar algumas brincadeiras, mas "pouca coisa" em relação ao todo. Se você já tem um conhecimento intermediário, certamente poderá se aborrecer com a serenidade que estou abordando o assunto, mas o objetivo é conseguir por a mão na massa.
Construindo um perceptron multicamada
No artigo Deep Learning Com Keras discorri também sobre o modelo Sequential, não deixe de ler o artigo. Podemos criar o modelo com uma certa facilidade passando uma lista de instâncias de camadas para o construtor, simplesmente com uma linha em Python:
model = Sequential()
Também citei que a primeira camada é explícita, as intermediárias são ocultas e por fim, temos uma camada de saída. Precisaremos então ter essa camada explícita no nosso código. O model precisa saber que formato de entrada esperar.
Utilizaremos uma rede neural com camadas completamente conectadas. Para isso, utilizaremos a Dense. A operação de implementação tem o formato:
output = activation(dot(input, kernel) + bias)
Perceba que sem a função de ativação, a camada densa consistirá apenas de duas operações lineares, sendo um dot product e uma addition.
Na primeira camada, a ativação recebe o argumento **relu,**seguido por input_shape. Trata-se de um array de entrada no formato (n,) ou (*,n). O primeiro argumento se refere ao número de unidades ocultas. Ficará cada vez mais claro, não se preocupe.
Tem mais algumas coisas importantes no meio, mas quero abstrair ao máximo e ir aprofundando devagar, conforme a necessidade de explicitar o recurso.
A camada final será também uma sigmoid, sendo uma probabilidade, como citado mais acima. Isso significa que este resultado receberá um score entre 0 e 1, sendo 0 para vinho branco e 1 para vinho tinto (porque assim definimos).
# Importamos o model Sequential
from keras.models import Sequential
# Importamos Dense para multicamada
from keras.layers import Dense
# Inicializamos o modelo
model = Sequential()
# Criamos a camada de entrada
model.add(Dense(12, activation='relu', input_shape=(11,)))
# Adicionamos uma camada oculta
model.add(Dense(8, activation='relu'))
# Adicionamos uma saida
model.add(Dense(1, activation='sigmoid'))
As 12 unidades ocultas na primeira camada do modelo é a dimensionalidade do espaço de saída. Essa configuração se refere à liberdade dada à rede para quando ela estiver aprendendo suas representações. Com mais unidades ocultas, será possível representações mais complexas, ao custo de mais processamento. O escalonamento ficará a seu critério e poderá ser feito por experimentação. O excesso também não é bom, podendo gerar erros. Há algum tempo pude experimentar isso online, vou procurar novamente para fazer um vídeo demonstrando que não necessariamente "mais é melhor".
Outra coisa importante a considerar é que quando não se têm uma quantidade considerável de dados, é melhor dar preferência a uma rede menor, com menos camadas ocultas, como por exemplo, apenas uma.
Uma coisa extremamente agradável é a possibilidade de se obter alguma informação sobre o modelo criado. Pode-se utilizar o atributo output_shape ou a função summary. Ou outras:
model.output_shape
model.summary()
model.get_config()
model.get_weights()
Um pedacinho da saída desse exemplo:



Compilação e ajuste do modelo
loss
A função de compilação recebe 3 parâmetros. O primeiro é a função é utilizada em otimizações matemáticas, estatística, economia e, entre outros, deep learning. Trata0se de uma função que mapeia um evento ou valores de uma ou mais variáveis em um número real, represntando algum custo associado ao evento. Por isso, chamada de "perda" nesse caso. A função utilizada no exemplo é a de entropia cruzada binária. Entropia é a desordem caótica dos números, precisamente para esse caso.
Para regressão, usualmente se utiliza Mean Squared Error (MSE). "Acho" que em português deva ser a "raiz quadrática do erro".
optimization
O algorítimo de otimização em deep learning pode significar uma diferença de minutos a dias no processo. A otimização adam é uma extensão para gradiente de descida estocástica (bonito nome, não?) adotado em deep learning e também em visão computacional. Ele é utilizado para manipulação dos pesos. Por enquanto, é informação o suficiente.
metrics
Esse parâmetro opcional permite passar, por exemplo, o parâmetro "accuracy" para monitorar a acurácia do treinamento.
epochs
Trata-se do número de interações com a amostragem. 20 interações significa um repasse de X_train e Y_train 20 vezes, em lotes de 1 amostragem (batch_size=1).
batch_size
O número de amostragens por interação, conforme descrito acima.
verbose
Se configurado para 1, será mostrado um progress bar durante o processo.
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(X_train, y_train,epochs=20, batch_size=1, verbose=1)
Predição
Repare que quase não tem código, o grande problema de um modelo simples como esse realmente é a quantidade de conceitos envolvidos, mas logo se tornará natural, para todos nós.
y_pred = model.predict(X_test)
Código completo
Dadas as explicações, agora vamos ao código final. Se você pulou direto para cá, lamento dizer que se deu mal.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from keras.models import Sequential
from keras.layers import Dense
white = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv", sep=';')
red = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv", sep=';')
red['type'] = 1
white['type'] = 0
wines = red.append(white, ignore_index=True)
X = wines.ix[:,0:11]
y = np.ravel(wines.type)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
scaler = StandardScaler().fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
model = Sequential()
model.add(Dense(12, activation='relu', input_shape=(11,)))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(X_train, y_train,epochs=20, batch_size=1, verbose=1)
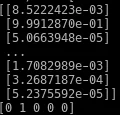
y_pred = model.predict(X_test)
print(y_pred)
print(y_test[:5])
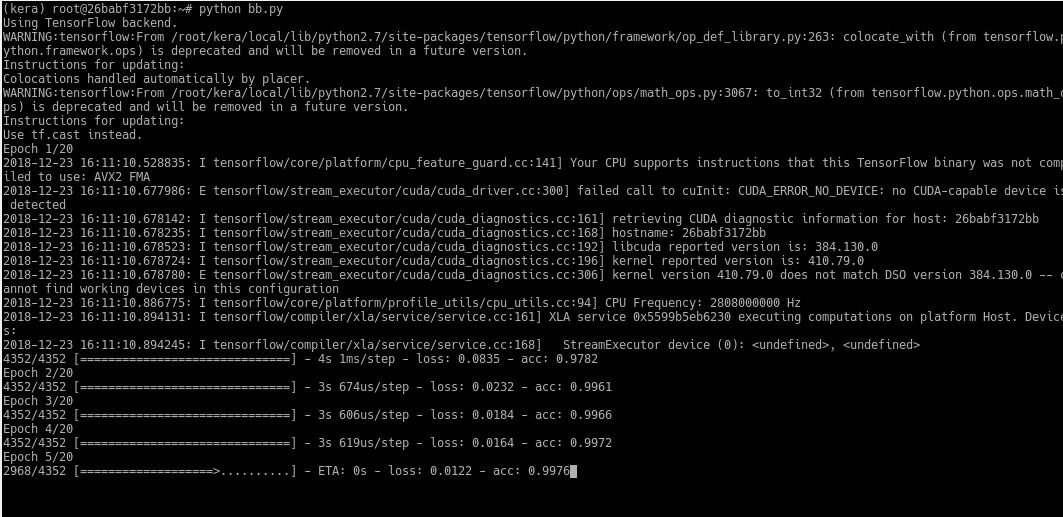
O treinamento é a imagem de destaque. Repare que a acurácia está acima de 99%. Abaixo, o resultado da predição.


Vamos melhorar o entendimento no próximo artigo, utilizando um exemplo que eu gostei bastante e que abrirá mais horizontes.
Até a próxima!
Inscreva-se no nosso canal Manual do Maker no YouTube.
Também estamos no Instagram.



Djames Suhanko
Autor do blog "Do bit Ao Byte / Manual do Maker".
Viciado em embarcados desde 2006.
LinuxUser 158.760, desde 1997.