




Manual
do
Maker
.
com
Como fazer predição com MNIST usando arquivos externos


Eu não sei se procurei errado, mas não achei "1" tutorial mostrando como fazer predição com MNIST sem ser utilizando arquivos do dataset. Talvez seja básico demais para alguém dar importância, sei lá. De qualquer modo, resolvi experimentar e compartilhar com vocês, tenho certeza que será do interesse de mais pessoas.
Predição com MNIST
O MNIST é um dataset consagrado, acredito que seja o "hello world" das redes neurais até. Todos os projetos o utilizam como exemplo´ TensorFlow, Theano, Caffe, Keras etc. Mas tudo o que se encontra nesses tutoriais é a construção do model e a predição com a base de testes. Vamos além, fazendo predição com arquivos do disco e minhas impressões.
Salvar o model
Para o MNIST é bastante simples compilar toda a vez que for utilizar. Coisa de 5 epochs e o model já estará em seu melhor estado. Fazer muitos repasses é problemático por causa de overfitting, que é quando a rede pára de aprender e começa a "viciar" nos dados do dataset. Daí, qualquer predição externa resultará em falso-positivo. Com apenas 1 epoch já consegue-se obter um bom resultado e para testes em CPU o MNIST também é uma boa opção. De qualquer modo, com 6 epochs já é bom considerar o salvamento do model. Para tanto, é necessário apenas uma chamada após compilar a rede neural, passando o nome do arquivo como referência. O problema é que em meus testes eu costumo salvar cópias das redes neurais para fazer testes sem modificar a versão anterior (usar git para isso acho que daria mais trabalho) e por vezes esquecia de mudar o nome do arquivo. Por isso, coloquei ao inicio do programa a definição do nome do model baseado no nome do arquivo, assim não precisa mais mudar o nome e vira uma rotina para os próximos programas:
model_name = str(sys.argv[0]).split(".")[0]+".h5"
E após chamar a função fit, basta chamar a função save_weights para salvar os pesos. No caso do código utililzado para esse artigo, o objeto do model está nomeado como cnn_n. Então:
cnn_n.save_weights(model_name, overwrite=True)
Criei uma função para o model, facilitando assim ter várias modelagens para testes. Basta chamar a respectiva função que se deseja utilizar na compilação do model:
def base_model():
model = Sequential()
# add model layers
model.add(Conv2D(64, kernel_size=3, activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(15, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return model
Outra função para agilizar o processo é a de conversão da imagem externa para o formato de array necessário. Sempre vai precisar de um tapinha, mas é melhor do que escrever tudo de novo:
def img_to_array(img, image_data_format='default'):
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.bitwise_not(img)
if image_data_format == "default":
image_data_format = K.image_data_format()
if image_data_format not in ['channels_first', 'channels_last']:
raise Exception('Unknown image_data_format: ', image_data_format)
x = np.asarray(img, dtype=K.floatx())
# colored image
# (channel, height, width)
if len(x.shape) == 3:
if image_data_format == 'channels_first':
x = x.transpose(2, 0, 1)
# grayscale
elif len(x.shape) == 2:
# already for th format
x = np.expand_dims(x, axis=0)
if image_data_format == 'channels_last':
# (height, width, channel)
#o canal esta no 2. estranho, mas...
#(height, channel, width)
x = x.reshape((x.shape[1], x.shape[2], x.shape[0]))
#print("CHANNEL")
#print(x.shape[2])
# unknown
else:
raise Exception('Unsupported image shape: ', x.shape)
return x
Sei que do jeito que fiz para manipular a imagem para o MNIST não é correta, porque enquanto analisava os dados percebi anomalias no formato, mas quebrou o galho, como você vai ver mais adiante.
O restante é meio padrão. Coloquei uma validação de argumentos para saber se é para treinar ou se é para predizer. Se não houver argumentos, ele inicia o treinamento, senão, varre o parâmetro em busca de arquivos. O parâmetro deve ser o nome de um diretório.
if len(sys.argv) == 1:
cnn_n = base_model()
cnn_n.summary()
cnn = cnn_n.fit(x_train, y_train, batch_size=batch_size, epochs=epochz, validation_data=(x_test,y_test),shuffle=True)
cnn_n.save_weights(model_name, overwrite=True)
scores = cnn_n.evaluate(x_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1] * 100))
Se for para predizer, pressupõe-se que o modelo já foi treinado, portanto basta carregá-lo do HD/SSD. Se for treinamento, logo após o fit ele será salvo, como nota-se na porção de código disposto acima.
Código completo
Esse programa leva um pouco de OpenCV para converter imagens RGB em escala de cinza, assim como exibir a imagem na tela, plotando o valor da predição.
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten
from keras import backend as K
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers import Dropout
import numpy as np
import cv2
import sys
import os
import time
print("ZERO")
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print("Numero de classes")
print(np.unique(y_train))
x_train = x_train.reshape(60000,28, 28, 1)
x_test = x_test.reshape(10000,28,28, 1)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
global num_pixels
num_pixels = x_train.shape[1] * x_train.shape[2]
model_name = str(sys.argv[0]).split(".")[0]+".h5"
batch_size = 32 #menos exemplos, mais updates
num_classes = 10
epochz = 6 #Nao precisa mais que 1 epoch para o MNIST. Evite overfitting
global density
density = 128
def img_to_array(img, image_data_format='default'):
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.bitwise_not(img)
if image_data_format == "default":
image_data_format = K.image_data_format()
if image_data_format not in ['channels_first', 'channels_last']:
raise Exception('Unknown image_data_format: ', image_data_format)
x = np.asarray(img, dtype=K.floatx())
# colored image
# (channel, height, width)
if len(x.shape) == 3:
if image_data_format == 'channels_first':
x = x.transpose(2, 0, 1)
# grayscale
elif len(x.shape) == 2:
# already for th format
x = np.expand_dims(x, axis=0)
if image_data_format == 'channels_last':
# (height, width, channel)
#o canal esta no 2. estranho, mas...
#(height, channel, width)
x = x.reshape((x.shape[1], x.shape[2], x.shape[0]))
#print("CHANNEL")
#print(x.shape[2])
# unknown
else:
raise Exception('Unsupported image shape: ', x.shape)
return x
def base_model():
model = Sequential()
# add model layers
model.add(Conv2D(64, kernel_size=3, activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(15, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return model
#se nao tem argumento para o programa, faz o treino e salva o model com o nome do script python
if len(sys.argv) == 1:
cnn_n = base_model()
cnn_n.summary()
cnn = cnn_n.fit(x_train, y_train, batch_size=batch_size, epochs=epochz, validation_data=(x_test,y_test),shuffle=True)
cnn_n.save_weights(model_name, overwrite=True)
scores = cnn_n.evaluate(x_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1] * 100))
#se tiver argumento, faz predicao do diretorio de imagem passado como parametro
else:
if not os.path.isdir(sys.argv[1]):
print("Directory not found. Exiting...")
exit(0)
#faz loop nos arquivos e limpa oa nomes pra nao ter LF
directory = sys.argv[1]
files = os.listdir(directory)
files = [w.replace("\n", "") for w in files]
#print(files)
#se for diretorio vazio, sai sem dar erro
if len(files) < 1:
print("There is no files in \'"+directory+"\' directory. Exiting...")
exit(0)
#...mas se tiver arquivos, deve fazer predicao
cnn_n = base_model()
cnn_n.load_weights(model_name)
font = cv2.FONT_HERSHEY_SIMPLEX
#ler imagens de um diretorio e redimensionar para o padrao do MNIST
for filename in files:
print(filename)
img = cv2.imread(directory + "/" +filename)
img = cv2.resize(img, (28, 28), 1)
xxx = img_to_array(np.float32(img) / 255.0)
xxx = np.expand_dims(xxx, axis=0)
start_t = time.time()
res = cnn_n.predict(xxx, verbose=0)
print("res.argmax e res 0 argmax")
print(res.argmax())
print(res[0][res.argmax()])
detected = res.argmax()
print(round(res[0][res.argmax()]*100), 3)
imgRead = cv2.imread(directory + "/" + filename, cv2.IMREAD_GRAYSCALE)
cv2.putText(imgRead, str(res.argmax()), (2, 22), font, 1, (100, 100, 100), 2, cv2.LINE_AA)
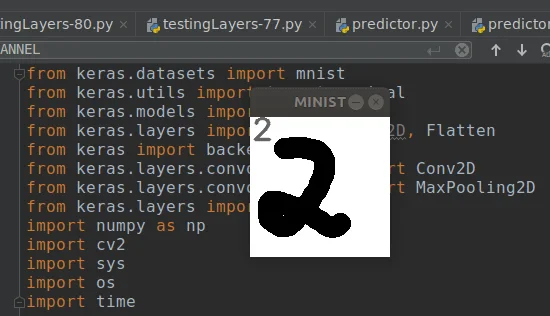
cv2.imshow("MINIST", imgRead)
pressed = cv2.waitKey(0)
if pressed == 27:
exit(0)
cv2.destroyAllWindows()
A compilação teve uma acurácia de quase 98% - o que não significa predição perfeita. O resultado da predição depende da qualidade do model, na variedade e quantidade de amostragens, na modelagem da rede, na densidade da rede, nas funções de ativação utilizadas, no número ideal de epochs e por fim, as imagens que serão passadas para a predição.
Acredito fortemente que não atingi um resultado melhor por falta de experiência, mas dentro do possível, tive um resultado satisfatório. E, se tratando do MNIST, foi possível deduzir um pouco do que ele espera para cada dígito. No vídeo eu mostro e explico as predições positivas e os falsos-positivos.
Sobre a predição com MNIST
Para compilar o modelo, basta executar o código disposto acima, sem passar parâmetros. Depois, passe o diretório contendo dígitos únicos para a predição.
Para fazer o teste, criei algumas imagens no Gimp, no formato 140x140, que é 5x o tamanho da imagem utilizada no modelo. No código está sendo feito o resize, a imagem de origem pode ser de qualquer tamanho, desde que mantenha as proporções.
Treinar o modelo
Para treinar o modelo:
python nome_do_arquivo_com_o_codigo.py
Se já tiver treinado um modelo e esqueceu de salvar os pesos antes de rodar o programa novamente, pode interromper com Ctrl+C durante a execução dos epochs.
Fazer predição
Para fazer a predição com MNIST, basta passar como parâmetro o nome do diretório contendo as imagens. Certifique-se de que o diretório tem apenas imagens, ainda que não sejam dígitos escritos à mão.
python seu_programa.py diretorio_de_imagens
O diretório de imagens deve estar no mesmo nível de diretório do programa.
Imagens do dataset do MNIST
O dataset é bastante padronizado, inclusive o formato dos dígitos são muito semelhantes, apesar de serem escritos à mão. Não estou dizendo que seja isso, mas parece que todos os dados foram escritos pela mesma pessoa. Na predição com MNIST os falsos-positivos eram os lideres. Daí dei uma olhada no formato das imagens do dataset e tentei escrever de forma parecida, porque minha escrita à mão é bem diferente e fiz minhas imagens de dígitos no Gimp, como já citei.



Uma das predições que deu certo depois que compreendi o que a rede neural esperava é a da imagem de destaque.
Vídeo
Tão logo seja possível, disponibilizo um vídeo no nosso canal DobitAoByteBrasil no Youtube mostrando a predição com MNIST. Se não é inscrito, passe por lá e se inscreva, clique no sininho e aguarde a notificação de vídeo novo, ok?
Se gostou do artigo, aproveite também para deixar seu like na nossa página do facebook, clicando ali em cima na coluna da direita.
Até a próxima!



Djames Suhanko
Autor do blog "Do bit Ao Byte / Manual do Maker".
Viciado em embarcados desde 2006.
LinuxUser 158.760, desde 1997.